
FAIRifying eWaterCycle: Towards reproducible science and better flooding forecasts
FAIRifying eWaterCycle
Towards reproducible science and better flooding forecasts
Growing populations, economies, industries and urbanization are increasing the demand for water, while extreme weather spurred by climate change is projected to lead to major changes in water availability. With more and more people moving into delta areas, more and more people become vulnerable to flooding. Naturally this increases the demand for flood forecasts. If we know that a flood is likely to happen in 10 days time, is there still something we can do to prevent this flood from actually happening? Can we take preparations to mitigate the effect of the flood?
This was exactly the aim of the eWaterCycle project: to predict flood and drought events 10 days in advance, worldwide and at unprecedentedly high resolution.
Reproducibility
While the complex system created in the eWaterCycle project worked for us, it was extremely difficult for someone else to set up such a system on their own computing resources, let alone to go back, rerun and validate our experiments. This is where the FAIR — Findability, Accessibility, Interoperability, and Reusability — principles come in, to serve as a guide around these issues, thereby maximizing the added value of the research. It is important to note that these principles not only apply to ‘data’ in the conventional sense, but also to how this data came to be. The issues identified by the FAIR principles are precisely the ones we tried to solve in the FAIRifying eWaterCycle project1.
In this project we created a fully reproducible (low resolution) version of the eWaterCycle forecast. The lessons learned will be taken into account moving forward in developing a community multi-model environment for hydrological experiments and analyses in the follow up project eWaterCycle II, but will also benefit the design of the European Open Science Cloud for Research.
In our effort to FAIRify the system, we relied heavily on both docker containerization and the Common Workflow Language (CWL). Containerization provides a solution to the problem of how to get software to run reliably when moved from one computing environment to another. CWL is a specification for describing analysis workflows and tools in a way that makes them portable and scalable across a variety of software and hardware environments, from workstations to cluster, cloud, and high performance computing (HPC) environments. In addition, CWL is able to provide provenance through CWLProv. Workflow provenance saves information about the workflow specification, input and outputs, and executions of the workflow, so that experiments can be verified and reproduced in a precise manner.
It is technically very hard to connect CWL workflow steps in a cyclic manner. Cyclic workflows are much better controlled using a specialized workflow engine for cycling systems. We therefore opted to only describe the workflow steps in CWL and control the workflow using such a workflow engine. Here we used Cylc: a workflow engine that orchestrates distributed suites of interdependent cycling tasks that may continue to run indefinitely. Cylc was originally developed for operational environmental forecasting. Having its roots in environmental forecasting, Cylc provides handy features for these kind of operational forecasts such as clock triggers, event triggers, retry handlers for individual tasks, and more. This allows us for example to wait for input data to be available on the server, retry specific tasks when they failed, or choose alternative paths of the workflow. Technical overview FAIRified eWaterCycle system
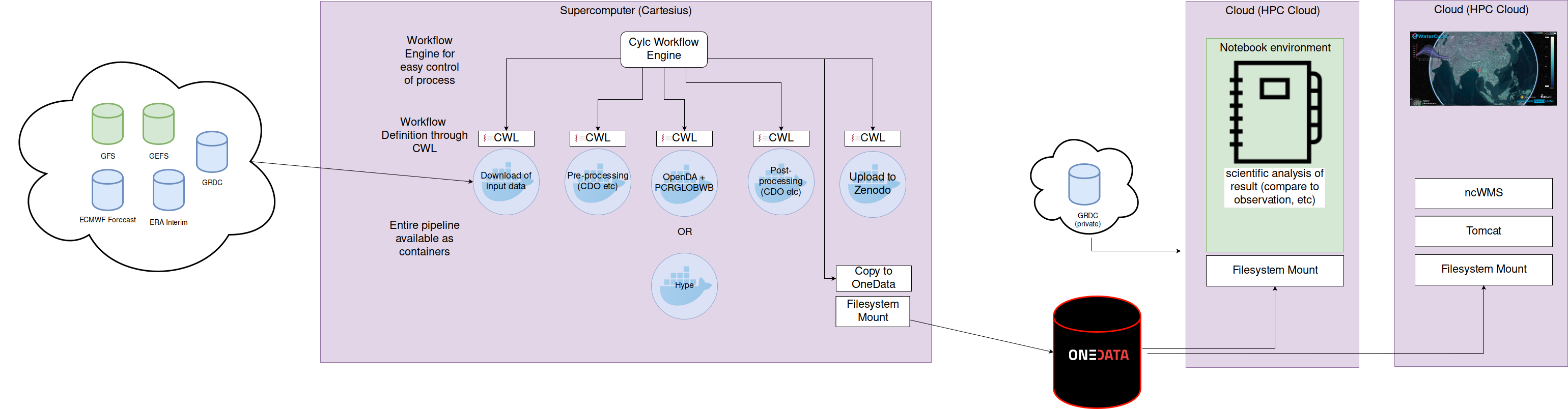
In essence, the forecast system (picture above) performs a couple of steps that are executed every day:
- Downloading of input data from various sources
- Pre-processing of input data
- Performing data-assimilation and running an ensemble of hydrological forecasts
- Post-processing of model output
- Uploading of the results and provenance to the archive
Results
Using a combination of the CWL standard for workflows, Cylc as a workflow engine, and Docker software containers, we were able to create a fully reproducible (low resolution) version of the eWaterCycle forecast. Output is stored at OneData and made available for analysis in a notebook environment. In addition the hydrological forecasts are visualized in a web application. The forecast is running daily now, without any manual intervention and runs on supercomputers without changes needed to the software installed on the system. Interactive forecast
](https://www.ewatercycle.org/assets/FAIRblog_fig3.png)
During this project we learned some valuable lessons that we plan to integrate into our larger eWaterCycle II project, with a focus on FAIR hydrological modelling. Some of the lessons learned during this small project include:
- You cannot build a FAIR system build on un-FAIR components. Sometimes you have no control on e.g. the FAIRness of your input data.
- Improving FAIRness of datasets from third parties is very difficult without involving the original author of such data. Involving authors of these datasets is often not feasible within the scope of small projects.
- Metadata and licensing information for datasets is often unclear or sometimes non-existent.
- The OneData system is a really nice concept, but could be further improved by adding some key usability features like file sharing, persistent storage with identifiers, authentication and authorization services and execution services for standards-based workflows.
Code and instructions available at eWaterCycle github
European Open Science Cloud for Research Pilot (EOSCPilot) Project and received funding from the European Commission’s Horizon 2020 research and innovation programme under the Grant Agreement no 739563.
-
This project is funded as part of the ↩