Future Model Runs#
Let us do some research now, with help of the CMIP6 dataset. We will look how our model fares with historical CMIP data and their climate models that predict future scenarios. I have setup some possible climate change models for you to use, you have to fill in your camel ID and think of a research question!
We like the sentence:
To understand [environment issue] in [region] we will study te impact of [verb/noun] on [hydrological variable].
But feel free to come up with your own! Some hints:
Maybe look at a smaller time period.
What do certain climate changes do to your region.
In This Notebook: Model runs with CMIP Forcing#
In this notebook we will do the model runs for the chosen areas with the generated forcing from the previous notebook. This will be used to do our research with!
Importing and setting up#
# Ignore user warnings :)
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
# Required dependencies
import ewatercycle.forcing
import ewatercycle.observation.grdc
import ewatercycle.analysis
from pathlib import Path
from cartopy.io import shapereader
import pandas as pd
import numpy as np
from rich import print
import xarray as xr
import shutil
import json
import ewatercycle
import ewatercycle.models
from util_functions import *
You can change the folder structure, but note that you will have to change that in upcoming notebooks as well!
# Load settings
# Read from the JSON file
with open("settings.json", "r") as json_file:
settings = json.load(json_file)
camel_id = settings["caravan_id"]
# Defining path for catchment shape file
central_path = "/data/shared/climate-data/camels_africa/zimbabwe/camel_data"
path_to_save = Path.home() / "my_data/workshop_zimbabwe"
path_to_save.mkdir(exist_ok=True, parents=True)
shape_file = central_path + "/shapefiles" + f"/{str(camel_id[:-2])}" + f"/{str(camel_id[:-2])}.shp"
data_file_nc = central_path + (f"/{camel_id}.nc")
my_data_nc = xr.open_dataset(data_file_nc, engine="netcdf4")
# Defining destination path for CMIP data
forcing_path_CMIP = path_to_save / "CMIP_forcing"
forcing_path_CMIP.mkdir(exist_ok=True)
# Model HBV destination path
model_path_HBV = path_to_save / "CMIP_HBV"
model_path_HBV.mkdir(exist_ok=True)
historical_start = "1964-11-01"
historical_end = "1979-11-30"
future_start_data = "2026-01-01"
future_end_data = "2099-12-31"
Loading in the CMIP forcings#
# Load the generated historical data
historical_location = forcing_path_CMIP / "historical" / "work" / "diagnostic" / "script"
historical = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=historical_location)
# Load the generated SSP126 data
ssp126_location = forcing_path_CMIP / "SSP126" / "work" / "diagnostic" / "script"
SSP126 = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=ssp126_location)
# Load the generated SSP245 data
ssp245_location = forcing_path_CMIP / "SSP245" / "work" / "diagnostic" / "script"
SSP245 = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=ssp245_location)
# Load the generated SSP585 data
ssp585_location = forcing_path_CMIP / "SSP585" / "work" / "diagnostic" / "script"
SSP585 = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=ssp585_location)
Using the parameters found earlier.
parameters_found = settings["hbv_parameters"]
# Si, Su, Sf, Ss, Sp
s_0 = np.array([0, 100, 0, 5, 0])
Setting up the models#
I took this bit from our Bachelor student Ischa, so thank you very much!
We put the forcings in a list and then we will use that to look through the models we created, using the BMI implementation.
NOTE: we use HBVLocal here to speed up the process. This is a model that just runs locally, without the setup of containers, which is proportionally heavier than the running of the actual model.
forcing_list = [SSP126, SSP245, SSP585, historical]
output = []
years = []
for forcings in forcing_list:
model = ewatercycle.models.HBVLocal(forcing=forcings)
config_file, _ = model.setup(
parameters=parameters_found,
initial_storage=s_0,
cfg_dir = model_path_HBV,
)
model.initialize(config_file)
Q_m = []
time = []
while model.time < model.end_time:
model.update()
Q_m.append(model.get_value("Q")[0])
time.append(pd.Timestamp(model.time_as_datetime))
output.append(Q_m)
years.append(time)
del Q_m, time
model.finalize()
Checking our results#
Finally, we look at the output and we use standard python libraries to visualize the results. We put the model output into a pandas Series to make plotting easier.
SSP126_output = pd.Series(data=output[0], name="SSP126", index=years[0])
SSP245_output = pd.Series(data=output[1], name="SSP245", index=years[1])
SSP585_output = pd.Series(data=output[2], name="SSP585", index=years[2])
historical_output = pd.Series(data=output[3], name="Historical", index=years[3])
# Saving the data for the next Notebook
SSP126_output.to_pickle(forcing_path_CMIP / "SSP126" / "output.pkl")
SSP245_output.to_pickle(forcing_path_CMIP / "SSP245" / "output.pkl")
SSP585_output.to_pickle(forcing_path_CMIP / "SSP585" / "output.pkl")
historical_output.to_pickle(forcing_path_CMIP / "historical" / "output.pkl")
Looking at the historical data modelling first.
my_data_nc['streamflow'].sel(date=slice(historical_start, historical_end)).plot(label="Observed streamflow")
historical_output.plot(label="HBV model on historical CMIP")
plt.ylabel("Q (mm/d)")
plt.xlabel("Year")
plt.grid()
plt.legend()
plt.show()
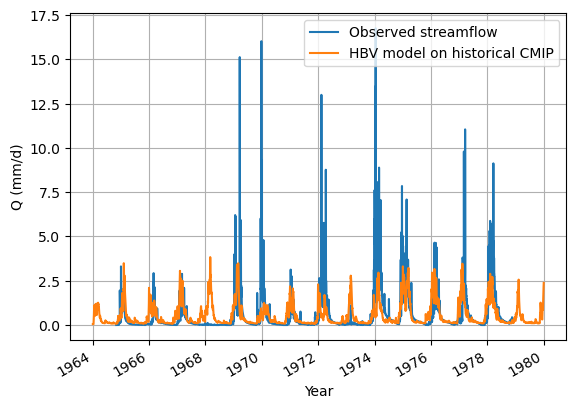
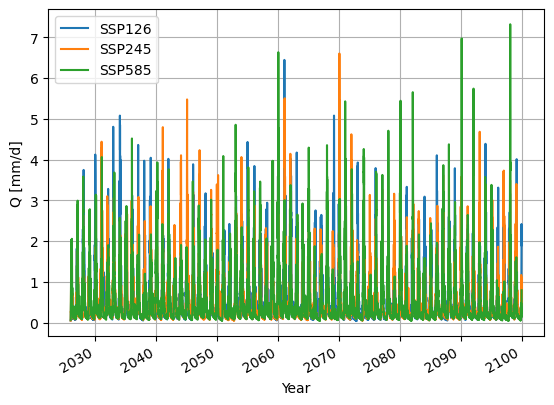
Now for the visualising you will look at the model outputs, which is, as you will see, pointless for this many years.
SSP126_output.plot()
SSP245_output.plot()
SSP585_output.plot()
plt.ylabel("Q [mm/d]")
plt.xlabel("Year")
plt.grid()
plt.legend()
plt.show()
Done with the model runs#
Now go to the next Notebook to do some research!