Calibrating HBV hydrological model run locally outside container forced with ERA5 forcing data#
In this notebook we will demonstrate how to calibrate the HBV model and works as an example of how to calibrate models in general.
We will use an extention to eWaterCycle: eWaterCycle-DA with DA for Data Assimilation. This package, developed by former MSc student David Haasnoot, adds functionality to deal with ensembles of models in eWaterCycle.
We do now run into a bit of a chicken and egg problem:
calibration of a model needs to be done before running the actual model experiment.
it is better to first demonstrate how to run a model before calibrating. But this requires calibration.
Therefore, too understand how models are run, please have a look at the step 3 notebook first before reading on.
# General python
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import numpy as np
from pathlib import Path
import pandas as pd
import matplotlib.pyplot as plt
import xarray as xr
import json
# Niceties
from rich import print
from tqdm import tqdm
from util_functions import create_forcing_data_HBV_from_nc
# General eWaterCycle
import ewatercycle
import ewatercycle.models
import ewatercycle.forcing
# We need the ewatercycle_DA package. If that is not available on your machine,
# uncomment the line below to install it
# !pip install ewatercycle-da
# eWaterCycle Data assimilation package
from ewatercycle_DA import DA
# Parameters
region_id = None
settings_path = "settings.json"
# Load settings
# Read from the JSON file
with open(settings_path, "r") as json_file:
settings = json.load(json_file)
print(settings)
{ 'country': 'Zimbabwe', 'caravan_id': 'AF_1491830.0', 'calibration_start_date': '1961-10-01T00:00:00Z', 'calibration_end_date': '1978-11-21T00:00:00Z', 'future_start_date': '2029-08-01T00:00:00Z', 'future_end_date': '2049-08-31T00:00:00Z', 'base_path': '/home/mmelotto/my_data/workshop_africa', 'central_data_path': '/data/shared/climate-data/camels_africa/zimbabwe/camel_data', 'path_shape': '/data/shared/climate-data/camels_africa/zimbabwe/camel_data/shapefiles/AF_1491830/AF_1491830.shp', 'path_caravan': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan', 'path_ERA5': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/ERA5', 'path_CMIP6': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/CMIP6', 'path_output': '/home/mmelotto/my_data/workshop_africa/output_data/AF_1491830.0', 'hbv_parameters': [10.0, 0.87, 592.0, 1.4, 0.3, 1.0, 0.09, 0.01, 0.001], 'SCE_calibration_parameters': [ 6.586012553845907, 1.0, 557.8536779504233, 2.939688843608312, 0.001, 1.0, 0.1, 0.00024827990873074545, 3.2087728977063117 ] }
Pre-generated observations of discharge from caravan#
Here we re-load the disharge data we generated in this notebook.
# Load the caravan forcing object
caravan_data_object = create_forcing_data_HBV_from_nc(settings["calibration_start_date"], settings["calibration_end_date"], settings["caravan_id"], settings["country"])
print(caravan_data_object)
LumpedMakkinkForcing( start_time='1961-10-01T00:00:00Z', end_time='1978-11-21T00:00:00Z', directory=PosixPath('/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan'), shape=PosixPath('/data/shared/climate-data/camels_africa/zimbabwe/camel_data/shapefiles/AF_1491830/AF_1491830.s hp'), filenames={ 'pr': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan/pr.nc', 'rsds': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan/rsds.nc', 'tas': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan/tas.nc', 'evspsblpot': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan/evspsblpot.nc', 'Q': '/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/caravan/Q.nc' } )
Pre-generated ERA5 forcing data for HBV model#
Here we load the ERA5 data we generated in this notebook
load_location = Path(settings['path_ERA5']) / "work" / "diagnostic" / "script"
ERA5_forcing_object = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=load_location)
print(ERA5_forcing_object)
LumpedMakkinkForcing( start_time='1961-10-01T00:00:00Z', end_time='1978-11-21T00:00:00Z', directory=PosixPath('/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/ERA5/work/diagnostic/scri pt'), shape=PosixPath('/home/mmelotto/my_data/workshop_africa/forcing_data/AF_1491830.0/ERA5/work/diagnostic/script/A F_1491830.shp'), filenames={ 'pr': 'OBS6_ERA5_reanaly_1_day_pr_1961-1978.nc', 'tas': 'OBS6_ERA5_reanaly_1_day_tas_1961-1978.nc', 'rsds': 'OBS6_ERA5_reanaly_1_day_rsds_1961-1978.nc', 'evspsblpot': 'Derived_Makkink_evspsblpot.nc' } )
Calibration basics and objective function#
In model calibration, we are looking for a set of parameters such that when the model is run with that set of parameters, we get the best model output. What “best” means differs per application or research question. In general, we like some model outputs to be as close as possible to observations. For this purpose we create an objective function that takes the model output of interest and observations as inputs and calculates some score that shows goodness of fit. Here we use a RMS difference function:
def calibrationObjective(modelOutput, observation, start_calibration, end_calibration):
'''A function that takes in two dataFrames, interpolates the model output to the
observations and calculates the average absolute difference between the two. '''
# Combine the two in one dataFrame
hydro_data = pd.concat([modelOutput.reindex(observation.index, method = 'ffill'), observation], axis=1,
keys=['model','observation'])
# Only select the calibration period
hydro_data = hydro_data[hydro_data.index > pd.to_datetime(pd.Timestamp(start_calibration).date())]
hydro_data = hydro_data[hydro_data.index < pd.to_datetime(pd.Timestamp(end_calibration).date())]
# Calculate RMS difference
squareDiff = (hydro_data['model'] - hydro_data['observation'])**2
rootMeanSquareDiff = np.sqrt(np.mean(squareDiff))
return rootMeanSquareDiff
Create an ensemble of models#
Instead of single model, we create an ensemble of models. In our case each ensemblemember is a HBV model that will get its own parameters. After running the entire ensemble we will apply the calibration objective function to determine the best set of parameters.
# Set the number of ensemble members. In Data Assimilation "ensemble member" and "particle" is used interchangeably
# Based on which school of DA you come from :-)
n_particles = 1000
# Create an array with parameter values.
# First set minimum and maximum values on the parameters
p_min_initial = np.array([0, 0.2, 40, .5, .001, 1, .01, .0001, 0.01])
p_max_initial = np.array([8, 1, 800, 4, .3, 10, .1, .01, 10.0])
# Create an empty array to store the parameter sets
parameters = np.zeros([len(p_min_initial), n_particles])
# Fill the array with random values between the minimum and maximum
for param in range(len(p_min_initial)):
parameters[param,:] = np.random.uniform(p_min_initial[param],p_max_initial[param],n_particles)
# Print parameter names and values for first ensemble member
param_names = ["Imax", "Ce", "Sumax", "Beta", "Pmax", "Tlag", "Kf", "Ks", "FM"]
print(list(zip(param_names, np.round(parameters[:,0], decimals=3))))
[ ('Imax', 2.188), ('Ce', 0.53), ('Sumax', 42.808), ('Beta', 1.113), ('Pmax', 0.288), ('Tlag', 4.524), ('Kf', 0.032), ('Ks', 0.007), ('FM', 0.248) ]
# Set initial state values
# Si, Su, Sf, Ss, Sp
s_0 = np.array([0, 100, 0, 5, 0])
# Each ensemble member gets their own parameters
# which are set during the initialize phase.
# Here we make a list of 'arguments' to pass to the model
# during initialize.
setup_kwargs_lst = []
for index in range(n_particles):
setup_kwargs_lst.append({'parameters': parameters[:,index],
})
# Create the ensemble object
ensemble = DA.Ensemble(N=n_particles)
ensemble.setup()
In the initialize step below we specify which model we will be using and pass the list of parameters. For other purposes (multimodel comparisons) here we could also provide lists of different models each with their own forcing and other setup arguments.
# This initializes the models for all ensemble members.
ensemble.initialize(model_name=["HBVLocal"]*n_particles,
forcing=[caravan_data_object]*n_particles,
setup_kwargs=setup_kwargs_lst)
# We appoint one of the ensemble members the role "reference model".
# In this use case, this is pure for timekeeping as shown in the next cell
ref_model = ensemble.ensemble_list[0].model
Models run with one command.#
All models can be run with the ensemble.update() command.
n_timesteps = int((ref_model.end_time - ref_model.start_time) / ref_model.time_step)
time = []
lst_Q = []
for i in tqdm(range(n_timesteps)):
time.append(pd.Timestamp(ref_model.time_as_datetime.date()))
ensemble.update()
lst_Q.append(ensemble.get_value("Q").flatten())
40%|████ | 2506/6260 [14:14<20:38, 3.03it/s]
ensemble.finalize()
Find best parameter set#
By calculating the objective function for each model output, we can search the combination of parameters with the lowest objective function.
# Create a pandas dataframe to hold all the model outputs
Q_m_arr = np.array(lst_Q).T
df_ensemble = pd.DataFrame(data=Q_m_arr[:,:len(time)].T,index=time,columns=[f'particle {n}' for n in range(n_particles)])
# Create a dataframe for the observations
ds_observation = xr.open_mfdataset([caravan_data_object['Q']]).to_pandas()
objective_values_calibration = []
for i in tqdm(range(n_particles)):
objective_values_calibration.append(calibrationObjective(df_ensemble.iloc[:,i],ds_observation["Q"],
settings['calibration_start_date'],
settings['calibration_end_date']))
100%|██████████| 1000/1000 [00:01<00:00, 787.71it/s]
# Make some plot of the spread of the objective functions for the different parameters
xFigNr = 2
yFigNr = 4
fig, axs = plt.subplots(xFigNr, yFigNr,figsize = (15,15))
for xFig in range(xFigNr):
for yFig in range(yFigNr):
paramCounter = xFig*yFigNr + yFig
axs[xFig,yFig].plot(parameters[paramCounter,:],objective_values_calibration,'.')
axs[xFig,yFig].set_title(param_names[paramCounter])
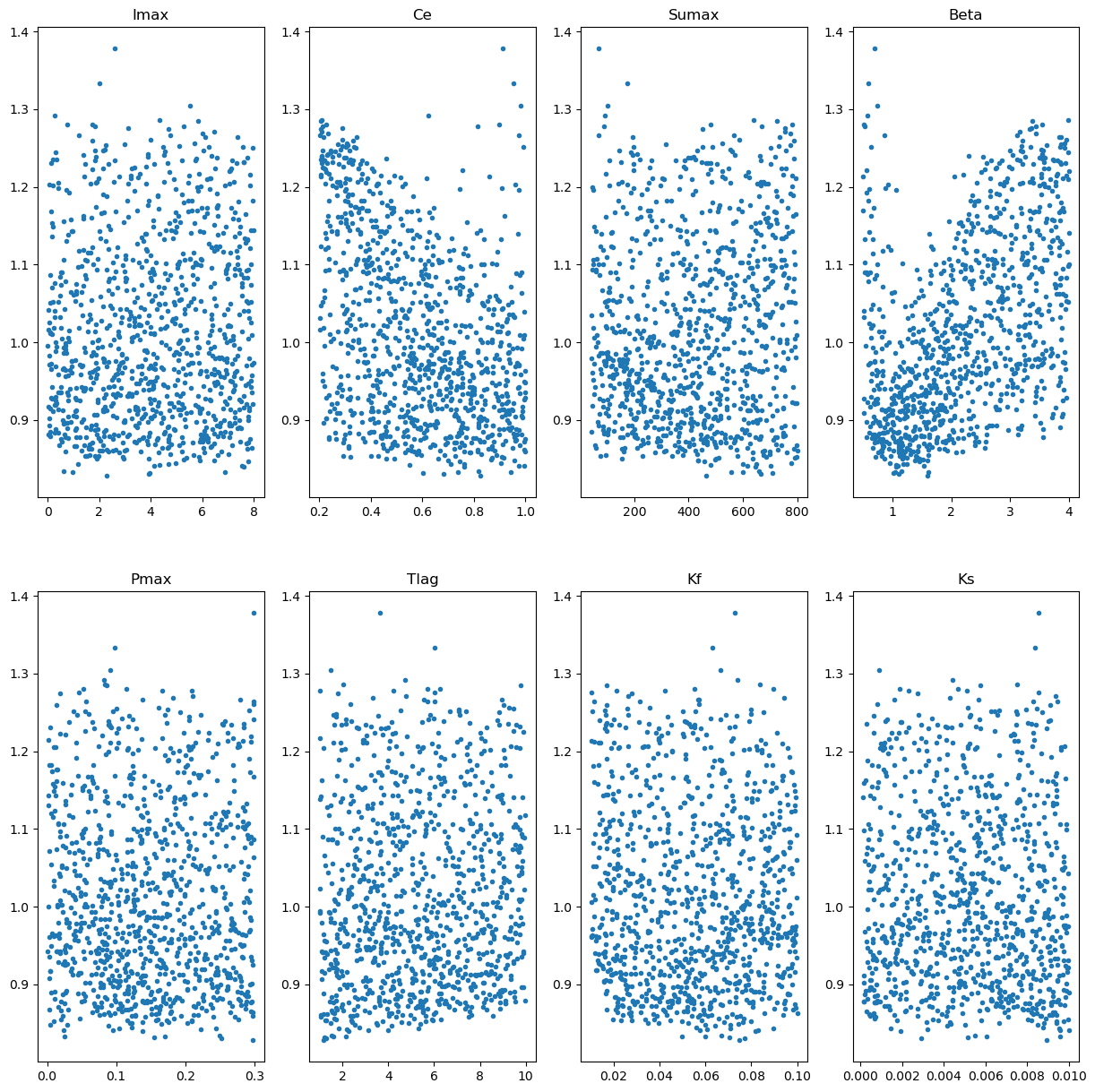
# Let's also print the minimal values:
parameters_minimum_index = np.argmin(np.array(objective_values_calibration))
parameters_minimum = parameters[:,parameters_minimum_index]
print(list(zip(param_names, np.round(parameters_minimum, decimals=3))))
[ ('Imax', 2.281), ('Ce', 0.824), ('Sumax', 464.747), ('Beta', 1.598), ('Pmax', 0.298), ('Tlag', 1.183), ('Kf', 0.075), ('Ks', 0.009), ('FM', 5.606) ]
# Make a plot of the model output of the minimum value
ds_observation["Q"].plot(label="Observed discharge")
ax = df_ensemble.iloc[:,parameters_minimum_index].plot(lw=2.5, label="'Best' modelled discharge")
plt.legend()
plt.grid()
plt.title(f"{settings["country"]}")
plt.ylabel("Discharge [mm/d]")
plt.xlabel("Year")
plt.show()
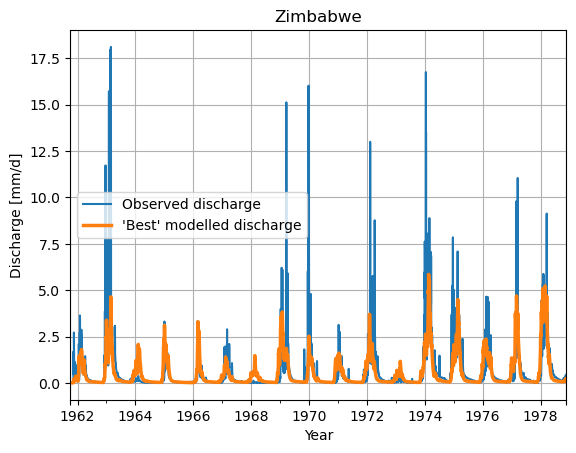
df_best = df_ensemble.iloc[:,parameters_minimum_index]
df_best.index = df_best.index.tz_localize("UTC")
# df_select = df_best.tz_convert("UTC")[settings['calibration_start_date']:settings['calibration_start_date']]
# Make a plot of the model output of the minimum value
ds_observation["Q"].plot(label="Observed discharge")
ax = df_best.plot(lw=2.5, label="Modelled discharge")
plt.legend()
plt.grid()
plt.title(f"{settings["country"]}")
plt.ylabel("Discharge [mm/d]")
plt.xlabel("Year")
plt.show()
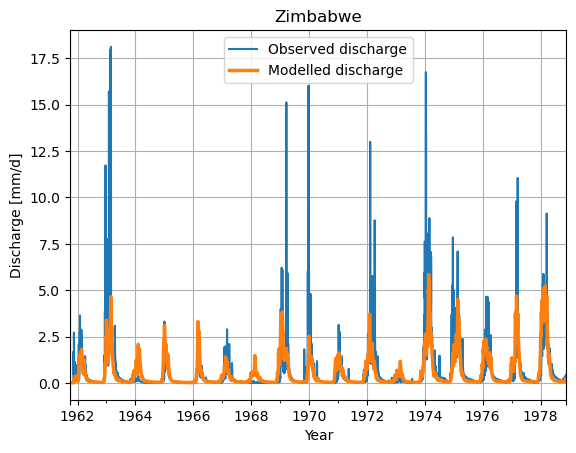
Save results#
We want to save these results to file to be able to load them in other studies
settings["monte_carlo_calibration_parameters"] = list(parameters_minimum)
# Write to a JSON file
with open("settings.json", "w") as json_file:
json.dump(settings, json_file, indent=4)
# Remove all temporary directories made by the optimization algo.
!rm -rf hbvlocal_*