![]()
PCRGlobWB example use case#
This example shows how the PCRGlobWB model can be used within the eWaterCycle system. It is assumed you have already seen this tutorial notebook explaining how to run the simple HBV model for the River Leven at Newby Bridge.
The PCRGlobWB model is an example of a distributed model where fluxes and stores in the balance are calculated for grid cells (often also called pixels). This requires both the forcing data as well as any parameters to also be spatially distributed. Depending on the complexity of the model, these datasets can be quite large in memory size.
Here we will be running PCRGLobWB for Great Brittain and will extract discharge data at the location of the River Leven again, to compare with the HBV model run. We will also demonstrate how to interact with the state of the model, during runtime, showcasing the benefit of using the BMI interface when building experiments using models.
# This cell is only used to suppress some distracting output messages
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import matplotlib.pyplot as plt
from cartopy import crs
from cartopy import feature as cfeature
from rich import print
import pandas as pd
import xarray as xr
from pathlib import Path
from datetime import datetime
from ipywidgets import IntProgress
from IPython.display import display
import fiona
import shapely.geometry
from pyproj import Geod
import ewatercycle.forcing
import ewatercycle.models
import ewatercycle.parameter_sets
station_latitude = 54.26935849558577 # Newby Bridge location from Google Maps
station_longitude = -2.9710855713537745
# Selecting our region again
camelsgb_id = "camelsgb_73010"
forcing_path_caravan = Path.home() / "forcing" / camelsgb_id / "caravan"
forcing_path_caravan.mkdir(exist_ok=True, parents=True)
pcr_glob_directory = Path("/data/shared/parameter-sets/pcrglobwb_global")
prepared_PCRGlob_forcing = Path.home() / "forcing" / camelsgb_id / "pcrglobwb" / "work/diagnostic/script"
experiment_start_date = "1997-08-01T00:00:00Z"
# 2 end dates: one use for is for the full run, but that takes a long time.
experiment_end_date = "2000-08-31T00:00:00Z"
# experiment_end_date = "1997-08-31T00:00:00Z"
Loading a parameter set#
For this example we have prepared and hosted a global parameter set made by Utrecht University. For each model run, what needs to be specified to deliniate the region of interest is a “clone map”. The config file has many options, one of which is the location of this clone map.
Note that this is very specific to PCRGlobWB. For complex (and legacy) models like PCRGlobWB one needs to know quite detailed information about the model before being able to run it. However, using eWaterCycle does reduce the time for seting up the model and getting it to run.
NOTE: an administrator will have to put your clonemap file in the correct directory!
parameter_set = ewatercycle.parameter_sets.ParameterSet(
name="custom_parameter_set",
directory=pcr_glob_directory,
config="./pcrglobwb_uk_05min.ini",
target_model="pcrglobwb",
supported_model_versions={"setters"},
)
print(parameter_set)
ParameterSet( name='custom_parameter_set', directory=PosixPath('/data/shared/parameter-sets/pcrglobwb_global'), config=PosixPath('pcrglobwb_uk_05min.ini'), doi='N/A', target_model='pcrglobwb', supported_model_versions={'setters'}, downloader=None )
Load forcing data#
For this example case, the forcing is generated in this seperate notebook. This is a common practice when generating forcing takes considerable (CPU, memory, disk) resources.
In the cell below, we load the pre-generated forcing. Note that in contrast with HBV, PCRGlobWB only needs temperature and precipitation as forcing inputs. Reminder: HBV also needs potential evaporation. PCRGlobWB calculated potential and actual evaporation as part of its update step.
forcing = ewatercycle.forcing.sources["PCRGlobWBForcing"].load(
directory=prepared_PCRGlob_forcing,
)
print(forcing)
PCRGlobWBForcing( start_time='1997-08-01T00:00:00Z', end_time='2000-08-31T00:00:00Z', directory=PosixPath('/home/mmelotto/forcing/camelsgb_73010/pcrglobwb/work/diagnostic/script'), shape=PosixPath('/home/mmelotto/forcing/camelsgb_73010/pcrglobwb/work/diagnostic/script/camelsgb_73010.shp'), filenames={}, precipitationNC='pcrglobwb_OBS6_ERA5_reanaly_1_day_pr_1997-2000_camelsgb_73010.nc', temperatureNC='pcrglobwb_OBS6_ERA5_reanaly_1_day_tas_1997-2000_camelsgb_73010.nc' )
Setting up the model#
Note that the model version and the parameterset versions should be compatible.
pcrglob = ewatercycle.models.PCRGlobWB(
parameter_set=parameter_set,
forcing=forcing
)
print(pcrglob)
PCRGlobWB( parameter_set=ParameterSet( name='custom_parameter_set', directory=PosixPath('/data/shared/parameter-sets/pcrglobwb_global'), config=PosixPath('pcrglobwb_uk_05min.ini'), doi='N/A', target_model='pcrglobwb', supported_model_versions={'setters'}, downloader=None ), forcing=PCRGlobWBForcing( start_time='1997-08-01T00:00:00Z', end_time='2000-08-31T00:00:00Z', directory=PosixPath('/home/mmelotto/forcing/camelsgb_73010/pcrglobwb/work/diagnostic/script'), shape=PosixPath('/home/mmelotto/forcing/camelsgb_73010/pcrglobwb/work/diagnostic/script/camelsgb_73010.shp' ), filenames={}, precipitationNC='pcrglobwb_OBS6_ERA5_reanaly_1_day_pr_1997-2000_camelsgb_73010.nc', temperatureNC='pcrglobwb_OBS6_ERA5_reanaly_1_day_tas_1997-2000_camelsgb_73010.nc' ) )
pcrglob.version
'setters'
eWaterCycle exposes a selected set of configurable parameters. These can be modified in the setup() method.
print(pcrglob.parameters)
dict_items([('start_time', '1997-08-01T00:00:00Z'), ('end_time', '1997-08-01T00:00:00Z'), ('routing_method', 'accuTravelTime'), ('max_spinups_in_years', '0')])
Calling setup() will start up the model container. Be careful with calling it multiple times!
cfg_file, cfg_dir = pcrglob.setup(
end_time=experiment_end_date,
# end_time="2000-08-31T00:00:00Z", # original end date takes about 22 minutes when alone on server, this is loaded later on, so no need to run it now :)
max_spinups_in_years=0
)
cfg_file, cfg_dir
('/home/mmelotto/projects/book/tutorials_examples/2_HBV_PCRGlobWB_ERA5/pcrglobwb_20251008_103625/pcrglobwb_ewatercycle.ini',
'/home/mmelotto/projects/book/tutorials_examples/2_HBV_PCRGlobWB_ERA5/pcrglobwb_20251008_103625')
print(pcrglob.parameters)
pcrglob_para = pcrglob.parameters
# Convert ISO 8601 strings to datetime objects
start_time = datetime.strptime(experiment_start_date, '%Y-%m-%dT%H:%M:%SZ')
end_time = datetime.strptime(experiment_end_date, '%Y-%m-%dT%H:%M:%SZ')
# Calculate the number of days for the progression bar
delta = end_time - start_time
number_of_days = delta.days
print(f"Number of days to model: {number_of_days}")
dict_items([('start_time', '1997-08-01T00:00:00Z'), ('end_time', '2000-08-31T00:00:00Z'), ('routing_method', 'accuTravelTime'), ('max_spinups_in_years', '0')])
Number of days to model: 1126
Note that the parameters have been changed. A new config file which incorporates these updated parameters has been generated as well. If you want to see or modify any additional model settings, you can acces this file directly. When you’re ready, pass the path to the config file to initialize().
pcrglob.initialize(cfg_file)
We prepare a small dataframe where we can store the discharge output from the model
time = pd.date_range(pcrglob.start_time_as_isostr, pcrglob.end_time_as_isostr)
timeseries = pd.DataFrame(
index=pd.Index(time, name="time"), columns=["PCRGlobWB: Leven"]
)
timeseries.head()
| PCRGlobWB: Leven | |
|---|---|
| time | |
| 1997-08-01 00:00:00+00:00 | NaN |
| 1997-08-02 00:00:00+00:00 | NaN |
| 1997-08-03 00:00:00+00:00 | NaN |
| 1997-08-04 00:00:00+00:00 | NaN |
| 1997-08-05 00:00:00+00:00 | NaN |
Running the model#
Simply running the model from start to end is straightforward. At each time step we can retrieve information from the model.
# Progress bar, since this can take a while
f = IntProgress(min=0, max=number_of_days) # instantiate the bar
display(f) # display the bar
while pcrglob.time < pcrglob.end_time:
pcrglob.update()
# Track discharge at station location
discharge_at_station = pcrglob.get_value_at_coords(
"discharge", lat=[station_latitude], lon=[station_longitude]
)
time = pcrglob.time_as_isostr
timeseries.loc[time, "PCRGlobWB: Leven"] = discharge_at_station[0]
# Update progress bar
f.value += 1
print("Model run finished!")
Model run finished!
Interacting with the model#
PCRGlobWB exposes many variables.
list(pcrglob.output_var_names)
['groundwater_recharge',
'lake_and_reservoir_storage',
'domesticWaterConsumptionVolume',
'land_surface_actual_evaporation',
'groundwater_storage',
'snow_melt',
'totalPotentialMaximumGrossDemand',
'interception_evaporation',
'flood_innundation_depth',
'total_groundwater_abstraction',
'water_body_actual_evaporation',
'interflow',
'consumptive_water_use_for_irrigation_demand',
'non_irrigation_gross_demand_volume',
'accumulated_total_surface_runoff',
'livestock_water_withdrawal',
'land_surface_potential_evaporation',
'total_groundwater_storage',
'bare_soil_evaporation',
'top_water_layer_evaporation',
'transpiration_from_irrigation',
'total_thickness_of_active_water_storage',
'domestic_water_withdrawal',
'netLqWaterToSoil_at_irrigation_volume',
'interception_storage',
'non_irrigation_gross_demand',
'livestockWaterConsumptionVolume',
'groundwater_depth_for_top_layer',
'surface_water_storage',
'irrigation_gross_demand_volume',
'return_flow_from_irrigation_demand_withdrawal',
'upper_soil_storage',
'desalination_source_abstraction_volume',
'snow_free_water_evaporation',
'surface_water_abstraction',
'industryWaterConsumptionVolume',
'fossil_groundwater_storage',
'evaporation_from_irrigation_volume',
'total_evaporation_fraction',
'evaporation_from_irrigation',
'direct_runoff',
'accumulated_land_surface_baseflow',
'snow_free_water',
'total_thickness_of_water_storage',
'precipitation',
'industryWaterWithdrawalVolume',
'net_liquid_water_to_soil',
'baseflow',
'return_flow_from_groundwater_abstraction',
'bottom_elevation_of_lowermost_layer',
'groundwater_head_for_layer_1',
'return_flow_from_non_irrigation_demand_withdrawal',
'domesticWaterWithdrawalVolume',
'top_water_layer',
'transpiration_from_irrigation_volume',
'total_gross_demand_volume',
'top_elevation_of_uppermost_layer',
'fraction_of_surface_water_allocation',
'total_groundwater_abstraction_volume',
'total_transpiration',
'precipitation_at_irrigation_volume',
'lower_soil_storage',
'land_surface_water_balance',
'water_body_potential_evaporation',
'netLqWaterToSoil_at_irrigation',
'groundwater_head_for_top_layer',
'fraction_of_other_water_source_allocation',
'infiltration',
'consumptive_water_use_for_non_irrigation_demand',
'irrigation_withdrawal',
'lower_soil_saturation_degree',
'fraction_of_desalinated_water_allocation',
'water_body_evaporation_fraction',
'non_paddy_irrigation_withdrawal',
'total_gross_demand',
'groundwater_capillary_rise',
'non_fossil_groundwater_abstraction',
'land_surface_evaporation_fraction',
'fraction_of_non_fossil_groundwater_allocation',
'groundwater_head_for_layer_2',
'flood_innundation_volume',
'paddy_irrigation_withdrawal',
'total_evaporation',
'local_water_body_flux',
'land_surface_evaporation',
'channel_storage',
'surface_water_level',
'accumulated_land_surface_runoff',
'lower_soil_transpiration',
'total_volume_of_water_storage',
'precipitation_at_irrigation',
'reference_potential_evaporation',
'upper_soil_saturation_degree',
'fossil_groundwater_abstraction',
'land_surface_runoff',
'total_abstraction',
'test',
'livestockWaterWithdrawalVolume',
'desalination_source_abstraction',
'discharge',
'groundwater_thickness_estimate',
'temperature',
'upper_soil_transpiration',
'snow_water_equivalent',
'total_runoff',
'transpiration_from_irrigation',
'fraction_of_surface_water',
'bottom_elevation_of_uppermost_layer',
'industry_water_withdrawal',
'relativeGroundwaterHead',
'total_fraction_water_allocation',
'groundwater_volume_estimate',
'groundwater_depth_for_layer_2',
'irrigation_gross_demand',
'groundwater_depth_for_layer_1',
'irrigationWaterWithdrawalVolume',
'surface_water_abstraction_volume']
Model fields can be fetched as xarray objects (or as flat numpy arrays using get_value()):
da = pcrglob.get_value_as_xarray("discharge")
da.thin(5) # only show every 5th value in each dim
<xarray.DataArray (longitude: 29, latitude: 22)> Size: 5kB
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.36099541e+00,
1.14954865e+00, 1.63362265e+00, 5.81284702e-01, 1.03070605e+00,
7.93194473e-01, 1.05944443e+00, 1.03646994e+00, 5.14641225e-01,
5.14155090e-01, 1.09502316e-01],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
1.22899306e+00, 0.00000000e+00, 9.28414345e-01, 1.26675928e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.72627318e+00,
5.43769693e+00, 4.03241968e+00, 1.58971059e+00, 1.55043983e+00,
1.14820147e+00, 6.18921757e-01],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
2.72685178e-02, 9.35214138e+00, 3.50451380e-01, 1.46504626e-01,
8.38614559e+00, 2.71886587e-01],
[0.00000000e+00, 0.00000000e+00, 6.52777791e-01, 0.00000000e+00,
0.00000000e+00, 1.04513891e-01, 0.00000000e+00, 0.00000000e+00,
...
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
1.59323442e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00]])
Coordinates:
* latitude (latitude) float64 176B -5.958 -5.542 -5.125 ... 2.375 2.792
* longitude (longitude) float64 232B 49.04 49.46 49.88 ... 59.88 60.29 60.71Xarray makes it very easy to plot the data. In the figure below, we add a cross at the location where we collected the discharge every timestep: Leven at Newby bridge.
fig = plt.figure(dpi=120)
ax = fig.add_subplot(111, projection=crs.PlateCarree())
da.plot(ax=ax, cmap="GnBu")
# Overlay ocean and coastlines
ax.add_feature(cfeature.OCEAN)
ax.add_feature(cfeature.RIVERS, color="k")
ax.coastlines()
# Add a red cross marker at the location of the Leven River at Newby Bridge
ax.scatter(station_longitude, station_latitude, s=250, c="r", marker="x", lw=2)
<matplotlib.collections.PathCollection at 0x7fb5490a3d40>
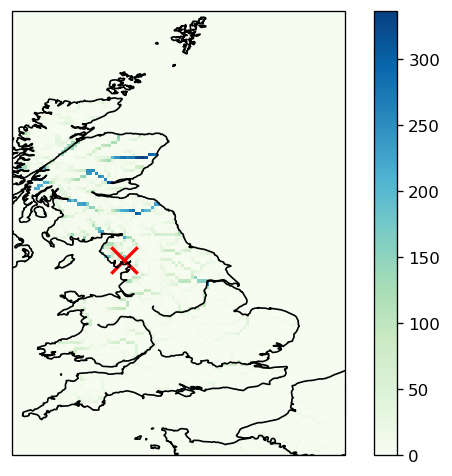
We can get (or set) the values at custom points as well:
# Extra
timeseries.plot()
plt.ylabel("Discharge $[m^3/s]$")
Text(0, 0.5, 'Discharge $[m^3/s]$')
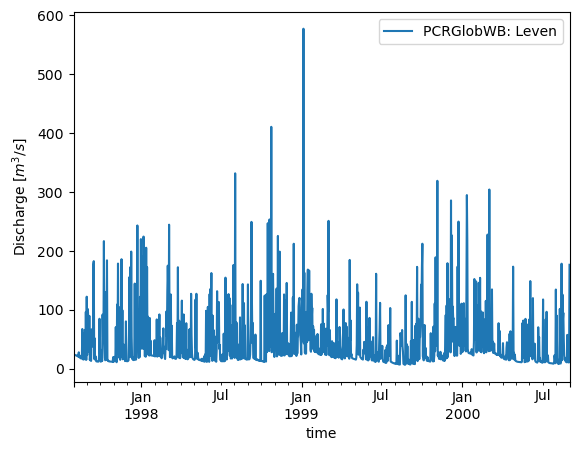
Looking at all the results#
We of course want to compare this both to observations as well as to the result of the HBV model.
camelsgb_forcing = ewatercycle.forcing.sources['CaravanForcing'].load(directory=forcing_path_caravan)
xr_camelsgb_forcing = xr.open_dataset(camelsgb_forcing['Q'])
xr_hbv_model_output = xr.open_dataset('~/river_discharge_data.nc')
# flux_out_Q unit conversion factor from mm/day to m3/s
conversion_mmday2m3s = 1 / (1000 * 86400)
shape = fiona.open(camelsgb_forcing.shape)
poly = [shapely.geometry.shape(p["geometry"]) for p in shape][0]
geod = Geod(ellps="WGS84")
poly_area, poly_perimeter = geod.geometry_area_perimeter(poly)
catchment_area_m2 = abs(poly_area)
print(f"{catchment_area_m2 = }")
xr_camelsgb_forcing["Q"] = xr_camelsgb_forcing["Q"] * conversion_mmday2m3s * catchment_area_m2
xr_hbv_model_output['Modelled_discharge'] = xr_hbv_model_output['Modelled_discharge']* conversion_mmday2m3s * catchment_area_m2
catchment_area_m2 = 248130958.76862004
timeseries.plot()
xr_camelsgb_forcing["Q"].plot(label="Observed discharge")
xr_hbv_model_output['Modelled_discharge'].plot(label="modelled discharge HBV")
plt.ylabel("Discharge [$m^3/s$]")
plt.xlabel("Date")
plt.legend()
<matplotlib.legend.Legend at 0x7fb54905d640>
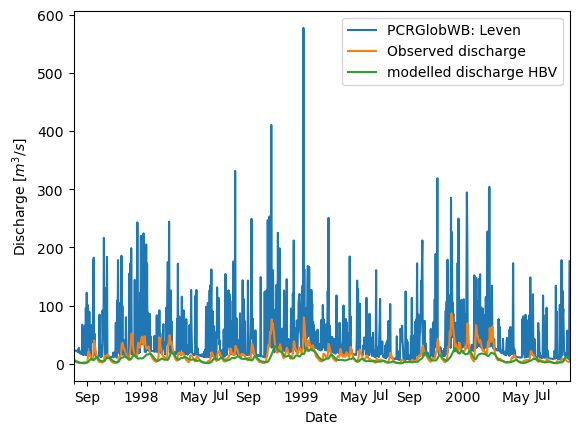
Doesn’t look too good for PCRGlobWB. This is because for this small area we are only looking at 10-ish pixels and most likely there is a big mismatch between the pixels that drain through the outlet in PCRGlobWB and the actual catchment. Typical areas for PCRGlobWB are more than 100x100 km.
Cleaning up#
Models usually perform some “wrap up tasks” at the end of a model run, such as writing the last outputs to disk and releasing memory. In the case of eWaterCycle, another important teardown task is destroying the container in which the model was running. This can free up a lot of resources on your system. Therefore it is good practice to always call finalize() when you’re done with an experiment.
pcrglob.finalize()